- Henry Ware suggested a modification to the builder with abstract members removing a lot of the boilerplate. Incidentally, this is a nice illustration of how nested types can be put to a good use in Scala.
- Justin ported the code to Haskell, which was very cool.
- A couple of commenters suggested that languages with support for default parameter values (like Python and Groovy) don't need elaborate constructs such as the builder pattern. There are two ways to respond. One is to remind that the intent of the pattern, specially as originally described in the GoF book, has little to do with optional data. The other is to acknowledge that I probably put too much emphasis on this issue and forgot to mention a very common idiom for building objects in Scala: just declare mandatory "parameters" as abstract vals and optional ones as concrete vals with default values, like so:
abstract class OrderOfScotch {
val brand:String
val mode:Preparation
val isDouble:Boolean
val glass:Option[Glass] = None
}
And to instantiate:val myDose = new OrderOfScotch {val brand = "Bobby Runner"; val mode = OnTheRocks; val isDouble = false} - I guess that's it. Thanks y'all.
Thursday, July 17, 2008
Comments on Comments on the Previous post
Wednesday, July 09, 2008
Type-safe Builder Pattern in Scala
The Builder Pattern is an increasingly popular idiom for object creation. Traditionally, one of it's shortcomings in relation to simple constructors is that clients can try to build incomplete objects, by omitting mandatory parameters, and that error will only show up in runtime. I'll show how to make this verification statically in Scala.
So, let's say you want to order a shot of scotch. You'll need to ask for a few things: the brand of the whiskey, how it should be prepared (neat, on the rocks or with water) and if you want it doubled. Unless, of course, you are a pretentious snob, in that case you'll probably also ask for a specific kind of glass, brand and temperature of the water and who knows what else. Limiting the snobbery to the kind of glass, here is one way to represent the order in scala.
A client can instantiate their orders like this:
Note that if the client doesn't want to specify the glass he can pass None as an argument, since the parameter was declared as Option[Glass]. This isn't so bad, but it can get annoying to remember the position of each argument, specially if many are optional. There are two traditional ways to circumvent this problem — define telescoping constructors or set the values post-instantiation with accessors — but both idioms have their shortcomings. Recently, in Java circles, it has become popular to use a variant of the GoF Builder pattern. So popular that it is Item 2 in the second edition of Joshua Bloch's Effective Java . A Java-ish implementation in Scala would be something like this:
. A Java-ish implementation in Scala would be something like this:
This is almost self-explanatory, the only caveat is that verifying the presence of non-optional parameters (everything but the glass) is done by the Option.get method. If a field is still None, an exception will be thrown. Keep this in mind, we'll come back to it later.
The var keyword prefixing the fields means that they are mutable references. Indeed, we mutate them in each of the building methods. We can make it more functional in the traditional way:
The scotch builder is now enclosed in an object, this is standard practice in Scala to isolate modules. In this enclosing object we also find a factory method for the builder, which should be called like so:
Looking back at the ScotchBuilder class and it's implementation, it might seem that we just moved the huge constructor mess from one place (clients) to another (the builder). And yes, that is exactly what we did. I guess that is the very definition of encapsulation, sweeping the dirt under the rug and keeping the rug well hidden. On the other hand, we haven't gained all the much from this "functionalization" of our builder; the main failure mode is still present. That is, having clients forget to set mandatory information, which is a particular concern since we obviously can't fully trust the sobriety of said clients*. Ideally the type system would prevent this problem, refusing to typecheck a call to build() when any of the non-optional fields aren't set. That's what we are going to do now.
One technique, which is very common in Java fluent interfaces, would be to write an interface for each intermediate state containing only applicable methods. So we would begin with an interface VoidBuilder having all our withFoo() methods but no build() method, and a call to, say, withMode() would return another interface (maybe BuilderWithMode), and so on, until we call the last withBar() for a mandatory Bar, which would return an interface that finally has the build() method. This technique works, but it requires a metric buttload of code — for n mandatory fields 2n interfaces should be created. This could be automated via code generation, but there is no need for such heroic efforts, we can make the typesystem work in our favor by applying some generics magic. First, we define two abstract classes:
Then, for each mandatory field, we add to our builder a generic parameter:
Next, have each withFoo method pass ScotchBuilder's type parameters as type arguments to the builders they return. But, and here is where the magic happens, there is a twist on the methods for mandatory parameters: they should, for their respective generic parameters, pass instead TRUE:
The second part of the magic act is to apply the world famous pimp-my-library idiom and move the build() method to an implicitly created class, which will be anonymous for the sake of simplicity:
Note the type of the parameter for this implicit method: ScotchBuilder[TRUE, TRUE, TRUE]. This is the point where we "declare" that we can only build an object if all the mandatory parameters are specified. And it really works:
So, we achieved our goal (see the full listing below). If you are worried about the enormous parameter lists inside the builder, I've posted here an alternative implementation with abstract members instead. It is more verbose, but also cleaner.
Now, remember those abstract classes TRUE and FALSE? We never did subclass or instantiate them at any point. If I'm not mistaken, this is an idiom named Phantom Types, commonly used in the ML family of programming languages. Even though this application of phantom types is fairly trivial, we can glimpse at the power of the mechanism. We have, in fact, codified all 2n states (one for each combination of mandatory fields) as types. ScotchBuilder's subtyping relation forms a lattice structure and the enableBuild() implicit method requires the supremum of the poset (namely, ScotchBuilder[TRUE, TRUE, TRUE]). If the domain requires, we could specify any other point in the lattice — say we can doll-out a dose of any cheap whiskey if the brand is not given, this point is represented by ScotchBuilder[_, TRUE, TRUE]. And we can even escape the lattice structure by using Scala inheritance. Of course, I didn't invent any of this; the idea came to me in this article by Matthew Fluet and Riccardo Pucella, where they use phantom types to encode subtyping in a language that lacks it.
EDIT 2008-07-09 at 19h00min: Added introductory paragraph.
So, let's say you want to order a shot of scotch. You'll need to ask for a few things: the brand of the whiskey, how it should be prepared (neat, on the rocks or with water) and if you want it doubled. Unless, of course, you are a pretentious snob, in that case you'll probably also ask for a specific kind of glass, brand and temperature of the water and who knows what else. Limiting the snobbery to the kind of glass, here is one way to represent the order in scala.
sealed abstract class Preparation /* This is one way of coding enum-like things in scala */
case object Neat extends Preparation
case object OnTheRocks extends Preparation
case object WithWater extends Preparation
sealed abstract class Glass
case object Short extends Glass
case object Tall extends Glass
case object Tulip extends Glass
case class OrderOfScotch(val brand:String, val mode:Preparation, val isDouble:Boolean, val glass:Option[Glass])
A client can instantiate their orders like this:
val normal = new OrderOfScotch("Bobby Runner", OnTheRocks, false, None)
val snooty = new OrderOfScotch("Glenfoobar", WithWater, false, Option(Tulip));Note that if the client doesn't want to specify the glass he can pass None as an argument, since the parameter was declared as Option[Glass]. This isn't so bad, but it can get annoying to remember the position of each argument, specially if many are optional. There are two traditional ways to circumvent this problem — define telescoping constructors or set the values post-instantiation with accessors — but both idioms have their shortcomings. Recently, in Java circles, it has become popular to use a variant of the GoF Builder pattern. So popular that it is Item 2 in the second edition of Joshua Bloch's Effective Java
class ScotchBuilder {
private var theBrand:Option[String] = None
private var theMode:Option[Preparation] = None
private var theDoubleStatus:Option[Boolean] = None
private var theGlass:Option[Glass] = None
def withBrand(b:Brand) = {theBrand = Some(b); this} /* returning this to enable method chaining. */
def withMode(p:Preparation) = {theMode = Some(p); this}
def isDouble(b:Boolean) = {theDoubleStatus = some(b); this}
def withGlass(g:Glass) = {theGlass = Some(g); this}
def build() = new OrderOfScotch(theBrand.get, theMode.get, theDoubleStatus.get, theGlass);
}This is almost self-explanatory, the only caveat is that verifying the presence of non-optional parameters (everything but the glass) is done by the Option.get method. If a field is still None, an exception will be thrown. Keep this in mind, we'll come back to it later.
The var keyword prefixing the fields means that they are mutable references. Indeed, we mutate them in each of the building methods. We can make it more functional in the traditional way:
object BuilderPattern {
class ScotchBuilder(theBrand:Option[String], theMode:Option[Preparation], theDoubleStatus:Option[Boolean], theGlass:Option[Glass]) {
def withBrand(b:String) = new ScotchBuilder(Some(b), theMode, theDoubleStatus, theGlass)
def withMode(p:Preparation) = new ScotchBuilder(theBrand, Some(p), theDoubleStatus, theGlass)
def isDouble(b:Boolean) = new ScotchBuilder(theBrand, theMode, Some(b), theGlass)
def withGlass(g:Glass) = new ScotchBuilder(theBrand, theMode, theDoubleStatus, Some(g))
def build() = new OrderOfScotch(theBrand.get, theMode.get, theDoubleStatus.get, theGlass);
}
def builder = new ScotchBuilder(None, None, None, None)
}The scotch builder is now enclosed in an object, this is standard practice in Scala to isolate modules. In this enclosing object we also find a factory method for the builder, which should be called like so:
import BuilderPattern._
val order = builder withBrand("Takes") isDouble(true) withGlass(Tall) withMode(OnTheRocks) build()
Looking back at the ScotchBuilder class and it's implementation, it might seem that we just moved the huge constructor mess from one place (clients) to another (the builder). And yes, that is exactly what we did. I guess that is the very definition of encapsulation, sweeping the dirt under the rug and keeping the rug well hidden. On the other hand, we haven't gained all the much from this "functionalization" of our builder; the main failure mode is still present. That is, having clients forget to set mandatory information, which is a particular concern since we obviously can't fully trust the sobriety of said clients*. Ideally the type system would prevent this problem, refusing to typecheck a call to build() when any of the non-optional fields aren't set. That's what we are going to do now.
One technique, which is very common in Java fluent interfaces, would be to write an interface for each intermediate state containing only applicable methods. So we would begin with an interface VoidBuilder having all our withFoo() methods but no build() method, and a call to, say, withMode() would return another interface (maybe BuilderWithMode), and so on, until we call the last withBar() for a mandatory Bar, which would return an interface that finally has the build() method. This technique works, but it requires a metric buttload of code — for n mandatory fields 2n interfaces should be created. This could be automated via code generation, but there is no need for such heroic efforts, we can make the typesystem work in our favor by applying some generics magic. First, we define two abstract classes:
abstract class TRUE
abstract class FALSE
Then, for each mandatory field, we add to our builder a generic parameter:
class ScotchBuilder[HB, HM, HD](val theBrand:Option[String], val theMode:Option[Preparation], val theDoubleStatus:Option[Boolean], val theGlass:Option[Glass]) {
/* ... body of the scotch builder .... */
}Next, have each withFoo method pass ScotchBuilder's type parameters as type arguments to the builders they return. But, and here is where the magic happens, there is a twist on the methods for mandatory parameters: they should, for their respective generic parameters, pass instead TRUE:
class ScotchBuilder[HB, HM, HD](val theBrand:Option[String], val theMode:Option[Preparation], val theDoubleStatus:Option[Boolean], val theGlass:Option[Glass]) {
def withBrand(b:String) =
new ScotchBuilder[TRUE, HM, HD](Some(b), theMode, theDoubleStatus, theGlass)
def withMode(p:Preparation) =
new ScotchBuilder[HB, TRUE, HD](theBrand, Some(p), theDoubleStatus, theGlass)
def isDouble(b:Boolean) =
new ScotchBuilder[HB, HM, TRUE](theBrand, theMode, Some(b), theGlass)
def withGlass(g:Glass) =
new ScotchBuilder[HB, HM, HD](theBrand, theMode, theDoubleStatus, Some(g))
}The second part of the magic act is to apply the world famous pimp-my-library idiom and move the build() method to an implicitly created class, which will be anonymous for the sake of simplicity:
implicit def enableBuild(builder:ScotchBuilder[TRUE, TRUE, TRUE]) = new {
def build() =
new OrderOfScotch(builder.theBrand.get, builder.theMode.get, builder.theDoubleStatus.get, builder.theGlass);
}Note the type of the parameter for this implicit method: ScotchBuilder[TRUE, TRUE, TRUE]. This is the point where we "declare" that we can only build an object if all the mandatory parameters are specified. And it really works:
scala> builder withBrand("hi") isDouble(false) withGlass(Tall) withMode(Neat) build()
res5: BuilderPattern.OrderOfScotch = OrderOfScotch(hi,Neat,false,Some(Tall))
scala> builder withBrand("hi") isDouble(false) withGlass(Tall) build()
<console>:9: error: value build is not a member of BuilderPattern.ScotchBuilder[BuilderPattern.TRUE,BuilderPattern.FALSE,BuilderPattern.TRUE]
builder withBrand("hi") isDouble(false) withGlass(Tall) build()So, we achieved our goal (see the full listing below). If you are worried about the enormous parameter lists inside the builder, I've posted here an alternative implementation with abstract members instead. It is more verbose, but also cleaner.
Now, remember those abstract classes TRUE and FALSE? We never did subclass or instantiate them at any point. If I'm not mistaken, this is an idiom named Phantom Types, commonly used in the ML family of programming languages. Even though this application of phantom types is fairly trivial, we can glimpse at the power of the mechanism. We have, in fact, codified all 2n states (one for each combination of mandatory fields) as types. ScotchBuilder's subtyping relation forms a lattice structure and the enableBuild() implicit method requires the supremum of the poset (namely, ScotchBuilder[TRUE, TRUE, TRUE]). If the domain requires, we could specify any other point in the lattice — say we can doll-out a dose of any cheap whiskey if the brand is not given, this point is represented by ScotchBuilder[_, TRUE, TRUE]. And we can even escape the lattice structure by using Scala inheritance. Of course, I didn't invent any of this; the idea came to me in this article by Matthew Fluet and Riccardo Pucella, where they use phantom types to encode subtyping in a language that lacks it.
object BuilderPattern {
sealed abstract class Preparation
case object Neat extends Preparation
case object OnTheRocks extends Preparation
case object WithWater extends Preparation
sealed abstract class Glass
case object Short extends Glass
case object Tall extends Glass
case object Tulip extends Glass
case class OrderOfScotch(val brand:String, val mode:Preparation, val isDouble:Boolean, val glass:Option[Glass])
abstract class TRUE
abstract class FALSE
class ScotchBuilder
[HB, HM, HD]
(val theBrand:Option[String], val theMode:Option[Preparation], val theDoubleStatus:Option[Boolean], val theGlass:Option[Glass]) {
def withBrand(b:String) =
new ScotchBuilder[TRUE, HM, HD](Some(b), theMode, theDoubleStatus, theGlass)
def withMode(p:Preparation) =
new ScotchBuilder[HB, TRUE, HD](theBrand, Some(p), theDoubleStatus, theGlass)
def isDouble(b:Boolean) =
new ScotchBuilder[HB, HM, TRUE](theBrand, theMode, Some(b), theGlass)
def withGlass(g:Glass) = new ScotchBuilder[HB, HM, HD](theBrand, theMode, theDoubleStatus, Some(g))
}
implicit def enableBuild(builder:ScotchBuilder[TRUE, TRUE, TRUE]) = new {
def build() =
new OrderOfScotch(builder.theBrand.get, builder.theMode.get, builder.theDoubleStatus.get, builder.theGlass);
}
def builder = new ScotchBuilder[FALSE, FALSE, FALSE](None, None, None, None)
}
* Did you hear that noise? It's the sound of my metaphor shattering into a million pieces
EDIT 2008-07-09 at 19h00min: Added introductory paragraph.
Tuesday, April 08, 2008
A couple of interesting DSLs
It may not yet be an industry tsunami, but there certainly is a growing wave of interest in Domain Specific Languages. As often happens when thinking about programming language design, there appears to be an excessive concern with syntax and little talk of semantics. Dave Thomas points out how much effort is wasted playing syntactic games to make code look like English; effort that would be better spent identifying and representing the domain. To prove his point he talks about make and active record and Groovy builders as examples of successful DSLs. I've stumbled upon some more examples of semantically interesting DSLs on a couple of papers and thought it would be worthwhile to share some stuff I learned in the process.
Kay
Alan Kay is one of the giants in our little science, known for his fearless disposition to carry out "big ideas". His most recent endeavor, partnering with Ian Piumarta and others, is a good example of that. The project is called "Steps Toward the Reinvention of Programming" and aims to build a complete software system, from the metal up to the applications, in under 20 KLOC. Some of that magic will be achieved through, you guessed it, domain specific languages. To quote from first published report.
The project is only a year-old, so it is understandably far from the goal of a full-system. But they have already delivered bits and pieces that give an idea of the path forward. A particularly cool part is their TCP/IP stack implementation. The first step in any networking stack is to unmarshal packet headers according to some specification. For IP we look in RFC-791 and find a lovely piece of ASCII art describing just that:
Most implementations just hardcode these definitions, and those for TCP, and for UDP, and so on. Of course the footprint of the traditional approach is too high for Kay and Piumarta purposes. They opted for a seemingly odd technique: just grab the data from the specifications. Here is, in its entirety, the code for unmarshaling IP headers:
This is actual working code. But wait; didn't they just swept the parsing dirt under the rug? The rug here being the code to parse this fine looking tables. Surprisingly, that code is a whopping 27 lines of clean grammar definitions with semantic actions. The "trick", so to speak, is the underlying parsing mojo provided my Piumarta's OMeta system. Which is, by the way, itself implemented in about 40 lines of OMeta code. Yeah, turtles all the way down and all that stuff...
Ok, this is all very cute, but I seem to have fallen on my own trap and can't stop talking about syntax. The next bit of this networking stack is a little more interesting, the problem now is to handle each incoming TCP packet according to a set of specified rules such as "in response to a SYN the server must reply with a SYN-ACK packet". Here is the code:
The set of rules above is nothing more than a grammar and the code to construct response packets is implemented as corresponding semantic actions. This snippet is much harder do grok than the pretty tables we just saw, but it's much more interesting as well. The crucial idea is to pattern-match on the stream of incoming packets looking for flag patterns and respond accordingly. What's nice is that they already had a well-honed pattern matching language in OMeta's Parsing Expression Grammars. I should note that a powerful parsing engine is not a Golden Hammer, but it is a useful and underutilized computational model. And realizing that is much more significant, IMHO, than the procrustean effort of trying to shoehorn "natural language" text into a general purpose programming language.
Pierce
Now let's turn our attention to a different kind of DSL, developed for the Harmony project led by Pierce at UPenn. The problem to solved here is synchronizing bookmark data among different browsers. Seems a far cry from "reinventing computer programming", but there are some intricacies involved, as we shall soon see. The basic approach taken is to transform each browser-specific representation to an abstract view, synchronize the data in this abstract form, and than propagate it back to the concrete form. If you squint hard enough you can see these transformations are a form of the general "view-update problem" known from database literature. Instead of extracting a view from a set of tables, updating it, and propagating the changes back to the original tables, they get an abstract representation from a concrete one, update it (the synchronization proper), and putback the modified data to the original concrete format. So, one concrete input for Mozila would be the following html-ish file:
The abstract representation of that data is :
That's a textual representation of a labeled tree. Each {..} is a tree node, subnodes are identified by a label (i.e. label -> {...} ) and stuff inside square brackets are lists. So, basically we have two tree "schemas" and wish to translate between them. Here is where domain specific languages will come into play. We could naively propose to just whip up a couple of XSLTs and be done with it. The get direction would be trivial, but the putback is trickier. Note that the abstract representation lacks information about the add_date of the bookmarks; this is because not all browsers store this data. In a way, the abstract format is a minimal subset of the kinds of data that each browser is interested in. So, the putback of new bookmarks coming from non-Mozilla browsers could just default to some arbitrary date value, but we don't want to lose the data we have for existing bookmarks! This rules-out using a simple stylesheet for the putback.
Essentially, this is why the view-update problem is an interesting research question. The relevance to this post is the path Harmony's team chose to solve it, building a bidirectional language*. It's similar to a functional language, but instead of functions they have lenses. A lens is a pair of functions, one for get (from the concrete to the abstract) and one for putback. A putback lens takes a modifed abstract element and the original concrete element, mapping to an update concrete element.
Rephrasing more formally, though diverging from the notation used in the paper, a lens L would be a pair of functions (Lg, Lp). Using A as the domain of abstract elements and C for the domain of the concrete elements, the functions would be defined in:
Any lens obeying this equations can be called "well-formed". To exemplify, here is the identity lens (the arrow pointing up is the get and the opposite is the putback):
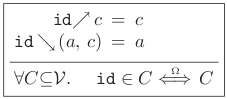
Absolutely uninteresting, as to be expected from any identity operation, but note that last line. It is the lens' type signature. Yes, this DSL has a full-blown type system! Take a look at a more interesting example, the map lens, which is analogous to the map function from functional programming:

The behavior isn't complicated, map is parametrized by another lens l, and just applies it to each subnode in the concrete tree for get. In the putback direction, it also just applies the putback for each element in the abstract tree, relying on the assumption that l behaves correctly for nodes missing in c. Now look at the scary type signature, which, to be perfectly honest, I don't fully comprehend myself. It is there to assure the well-formedness of map (and a couple of other properties), based on the type of l.
Lest I reproduce the entire paper here, and completely butcher it in the process, I'll cut to the final chapter of the story and show the program that maps between Mozilla's bookmark format and the abstract representation:
I'm afraid I'm unable to explain much of this program without going deeper than is appropriate here. But see how much is accomplished in probably fewer lines of code than would be required for expressing a mere transformation in XSLT . And of course, the whole bookmark synchronization thing is just a toy problem; the resulting system is powerful enough to tackle larger beasts. See the other papers in the project website, where they apply lenses to the traditional relational view-update problem, to character Strings and to data replication in distributed settings.
Wrapping up
Kay
Alan Kay is one of the giants in our little science, known for his fearless disposition to carry out "big ideas". His most recent endeavor, partnering with Ian Piumarta and others, is a good example of that. The project is called "Steps Toward the Reinvention of Programming" and aims to build a complete software system, from the metal up to the applications, in under 20 KLOC. Some of that magic will be achieved through, you guessed it, domain specific languages. To quote from first published report.
We also think that creating languages that fit the problems to be solved makes solving the problems easier, makes the solutions more understandable and smaller, and is directly in the spirit of our “active-math” approach. These “problem-oriented languages” will be created and used for large and small problems, and at different levels of abstraction and detail.
The project is only a year-old, so it is understandably far from the goal of a full-system. But they have already delivered bits and pieces that give an idea of the path forward. A particularly cool part is their TCP/IP stack implementation. The first step in any networking stack is to unmarshal packet headers according to some specification. For IP we look in RFC-791 and find a lovely piece of ASCII art describing just that:
+-------------+-------------+-------------------------+----------+----------------------------------------+
| 00 01 02 03 | 04 05 06 07 | 08 09 10 11 12 13 14 15 | 16 17 18 | 19 20 21 22 23 24 25 26 27 28 29 30 31 |
+-------------+-------------+-------------------------+----------+----------------------------------------+
| version | headerSize | typeOfService | length |
+-------------+-------------+-------------------------+----------+----------------------------------------+
| identification | flags | offset |
+---------------------------+-------------------------+----------+----------------------------------------+
| timeToLive | protocol | checksum |
+---------------------------+-------------------------+---------------------------------------------------+
| sourceAddress |
+---------------------------------------------------------------------------------------------------------+
| destinationAddress |
+---------------------------------------------------------------------------------------------------------+
Most implementations just hardcode these definitions, and those for TCP, and for UDP, and so on. Of course the footprint of the traditional approach is too high for Kay and Piumarta purposes. They opted for a seemingly odd technique: just grab the data from the specifications. Here is, in its entirety, the code for unmarshaling IP headers:
{ structure-diagram }
+-------------+-------------+-------------------------+----------+----------------------------------------+
| 00 01 02 03 | 04 05 06 07 | 08 09 10 11 12 13 14 15 | 16 17 18 | 19 20 21 22 23 24 25 26 27 28 29 30 31 |
+-------------+-------------+-------------------------+----------+----------------------------------------+
| version | headerSize | typeOfService | length |
+-------------+-------------+-------------------------+----------+----------------------------------------+
| identification | flags | offset |
+---------------------------+-------------------------+----------+----------------------------------------+
| timeToLive | protocol | checksum |
+---------------------------+-------------------------+---------------------------------------------------+
| sourceAddress |
+---------------------------------------------------------------------------------------------------------+
| destinationAddress |
+---------------------------------------------------------------------------------------------------------+
ip -- Internet Protocol packet header [RFC 791]
This is actual working code. But wait; didn't they just swept the parsing dirt under the rug? The rug here being the code to parse this fine looking tables. Surprisingly, that code is a whopping 27 lines of clean grammar definitions with semantic actions. The "trick", so to speak, is the underlying parsing mojo provided my Piumarta's OMeta system. Which is, by the way, itself implemented in about 40 lines of OMeta code. Yeah, turtles all the way down and all that stuff...
Ok, this is all very cute, but I seem to have fallen on my own trap and can't stop talking about syntax. The next bit of this networking stack is a little more interesting, the problem now is to handle each incoming TCP packet according to a set of specified rules such as "in response to a SYN the server must reply with a SYN-ACK packet". Here is the code:
['{ svc = &->(svc? [self peek])
syn = &->(syn? [self peek]) . ->(out ack-syn -1 (+ sequenceNumber 1) (+ TCP_ACK TCP_SYN) 0)
req = &->(req? [self peek]) . ->(out ack-psh-fin 0 (+ sequenceNumber datalen (fin-len tcp))
(+ TCP_ACK TCP_PSH TCP_FIN)
(up destinationPort dev ip tcp
(tcp-payload tcp) datalen))
ack = &->(ack? [self peek]) . ->(out ack acknowledgementNumber
(+ sequenceNumber datalen (fin-len tcp))
TCP_ACK 0)
;
( svc (syn | req | ack | .) | . ->(out ack-rst acknowledgementNumber
(+ sequenceNumber 1)
(+ TCP_ACK TCP_RST) 0)
) *
} < [NetworkPseudoInterface tunnel: '"/dev/tun0" from: '"10.0.0.1" to: '"10.0.0.2"]]
The set of rules above is nothing more than a grammar and the code to construct response packets is implemented as corresponding semantic actions. This snippet is much harder do grok than the pretty tables we just saw, but it's much more interesting as well. The crucial idea is to pattern-match on the stream of incoming packets looking for flag patterns and respond accordingly. What's nice is that they already had a well-honed pattern matching language in OMeta's Parsing Expression Grammars. I should note that a powerful parsing engine is not a Golden Hammer, but it is a useful and underutilized computational model. And realizing that is much more significant, IMHO, than the procrustean effort of trying to shoehorn "natural language" text into a general purpose programming language.
Pierce
Now let's turn our attention to a different kind of DSL, developed for the Harmony project led by Pierce at UPenn. The problem to solved here is synchronizing bookmark data among different browsers. Seems a far cry from "reinventing computer programming", but there are some intricacies involved, as we shall soon see. The basic approach taken is to transform each browser-specific representation to an abstract view, synchronize the data in this abstract form, and than propagate it back to the concrete form. If you squint hard enough you can see these transformations are a form of the general "view-update problem" known from database literature. Instead of extracting a view from a set of tables, updating it, and propagating the changes back to the original tables, they get an abstract representation from a concrete one, update it (the synchronization proper), and putback the modified data to the original concrete format. So, one concrete input for Mozila would be the following html-ish file:
<html>
<head> <title>Bookmarks</title> </head>
<body>
<h3>Bookmarks Folder</h3>
<dl>
<dt> <a href=\"www.google.com\"
add_date=\"1032458036\">Google</a> </dt>
<dd>
<h3>Conferences Folder</h3>
<dl>
<dt> <a href=\"www.cs.luc.edu/icfp\"
add_date=\"1032528670\">ICFP</a> </dt>
</dl>
</dd>
</dl>
</body>
</html>
The abstract representation of that data is :
{name -> Bookmarks Folder
contents ->
[{link -> {name -> Google
url -> www.google.com}}
{folder ->
{name -> Conferences Folder
contents ->
[{link ->
{name -> ICFP
url -> www.cs.luc.edu/icfp}}]}}]}
That's a textual representation of a labeled tree. Each {..} is a tree node, subnodes are identified by a label (i.e. label -> {...} ) and stuff inside square brackets are lists. So, basically we have two tree "schemas" and wish to translate between them. Here is where domain specific languages will come into play. We could naively propose to just whip up a couple of XSLTs and be done with it. The get direction would be trivial, but the putback is trickier. Note that the abstract representation lacks information about the add_date of the bookmarks; this is because not all browsers store this data. In a way, the abstract format is a minimal subset of the kinds of data that each browser is interested in. So, the putback of new bookmarks coming from non-Mozilla browsers could just default to some arbitrary date value, but we don't want to lose the data we have for existing bookmarks! This rules-out using a simple stylesheet for the putback.
Essentially, this is why the view-update problem is an interesting research question. The relevance to this post is the path Harmony's team chose to solve it, building a bidirectional language*. It's similar to a functional language, but instead of functions they have lenses. A lens is a pair of functions, one for get (from the concrete to the abstract) and one for putback. A putback lens takes a modifed abstract element and the original concrete element, mapping to an update concrete element.
Rephrasing more formally, though diverging from the notation used in the paper, a lens L would be a pair of functions (Lg, Lp). Using A as the domain of abstract elements and C for the domain of the concrete elements, the functions would be defined in:
Lg: C -> A
Lp: (C x A) -> C
So far we haven't gained much, but the above definitions allow us to express our requirements of "information conservation" as equations:
Lp(Lg(c), c) = c for all c in C
Lg(Lp(a, c)) = a for all a in A and c in C
Lp: (C x A) -> C
So far we haven't gained much, but the above definitions allow us to express our requirements of "information conservation" as equations:
Lp(Lg(c), c) = c for all c in C
Lg(Lp(a, c)) = a for all a in A and c in C
Any lens obeying this equations can be called "well-formed". To exemplify, here is the identity lens (the arrow pointing up is the get and the opposite is the putback):

Absolutely uninteresting, as to be expected from any identity operation, but note that last line. It is the lens' type signature. Yes, this DSL has a full-blown type system! Take a look at a more interesting example, the map lens, which is analogous to the map function from functional programming:

The behavior isn't complicated, map is parametrized by another lens l, and just applies it to each subnode in the concrete tree for get. In the putback direction, it also just applies the putback for each element in the abstract tree, relying on the assumption that l behaves correctly for nodes missing in c. Now look at the scary type signature, which, to be perfectly honest, I don't fully comprehend myself. It is there to assure the well-formedness of map (and a couple of other properties), based on the type of l.
Lest I reproduce the entire paper here, and completely butcher it in the process, I'll cut to the final chapter of the story and show the program that maps between Mozilla's bookmark format and the abstract representation:
link =
hoist *;
hd [];
hoist a;
rename * name;
rename href url;
prune add_date {$today};
wmap {name -> (hd []; hoist PCDATA)}
folder = hoist *;
xfork (*h} {name}
(hoist *t;
hd [];
rename dl contents)
wmap {name -> (hoist *;
hd [];
hoist PCDATA)
contents -> (host *;
list_map item)}
item =
wmap {dd -> folder, dt -> link};
rename_if_present dd folder;
rename_if_present dt link
bookmarks =
hoist html;
hoist *l
tl {|head --> {| * --> [ {|title --> {|* -->
[{|PCDATA --> Bookmarks|}]|}|}]|}|};
hd [];
hoist body;
folder
I'm afraid I'm unable to explain much of this program without going deeper than is appropriate here. But see how much is accomplished in probably fewer lines of code than would be required for expressing a mere transformation in XSLT . And of course, the whole bookmark synchronization thing is just a toy problem; the resulting system is powerful enough to tackle larger beasts. See the other papers in the project website, where they apply lenses to the traditional relational view-update problem, to character Strings and to data replication in distributed settings.
Wrapping up
- DSL design is language design, and that involves more than just syntax.
- Sometimes an well-known computational model can be repurposed to fit domain requirements, like Kay and Piumarta did adopting a grammar parsing engine to process a packet stream.
- Automata and similar non-turing-complete models can be very useful in Domain Specific Languages.
- Sometimes it pays to develop whole new semantics for your DSL.
- Of course there is little that is actually "wholly new" in the world. Taking Harmony's semantics for example, the team did apply a lot of domain theory to prove the totality of their lens combinators.
- If you can identify invariants that are hard to get right, it may pay to express them in a type system. But be warned that this is no child's play; even Pierce didn't go all the way to building a typechecker for his lenses.
- Have fun!
Subscribe to:
Posts (Atom)